“Customer focus”, and “customer centricity” are certainly very desirable traits for pretty much any business these days. With their growing popularity, the idea of “internal customers” has become mainstream. However, I have come to the conclusion that the “internal customer” concept self-deceptive. It avoids questioning some fundamental organizational beliefs. And in turn it avoids fundamental changes that are required for true customer centricity.
The Oxford Dictionary defines a customer as “a person who buys goods or services from a shop or business.” The opposite of the customer is the seller. A key aspect of the relationship with a customer, then, is the exchange of money. This definition alone debunks most of the “internal customers” I have ever seen, because none of them transfer money. They just consume work results for a downstream activity in a larger workflow.
The customer is someone outside your company that transfers money to the company in exchange for services or products. It’s the money your company needs to sustain its business. It’s the money your company needs to pay your wage. If that money comes from within, the business is not self-sustainable, and hence you cannot be customer focused (or centered, or oriented, …) on an internal customer. Some use the opportunity to change their focus from themselves (as in “We created this new request form to optimize our internal processes and reduce load on the team”) to those who use their work (as in “We created this new request form to make it easier for you to order what you need”). That’s a great first step. It is far from customer focus, though, as it is still internally focused.
One might argue that in an organization with strict internal service charges, we have internal customers, as those customers transfer money in exchange for services consumed. I have thought so myself for quite some time, at least on the condition that the internal customer is free to buy the same service elsewhere if he wishes (essentially, customer-centricity on forced customers is a joke). I have changed my view on that, though. As the money transferred in internal service charges is money that has been in the company before – it’s a game of left-pocket to right-pocket. From an economic perspective, it’s a zero-sum game for the company.
The German language has an interesting term to describe the actual role of an ‘internal customer’: “Abnehmer”. It has no direct translation in English. It means ‘those who take on your work results’. It might be translated as “consumer” or “receiver”. I dislike the passivity of ‘receiving’; I find it does not adequately describe the relationship. On the other hand, I’m uneasy with ‘consuming’ as it has the connotation of using something up. Lacking a better term (ideas welcome) I will use “consumer” in the remainder of this text, and I advocate to mentally as well as verbally separate the consumer of our work from the customer. In many cases, they are not the same people.
It is important because teams or departments that are not directly connected to the actual customer (and especially in larger organizations, this might be most of the organization) will behave differently, depending on whom (they think) they serve. The ‘internal customer’ is an important yet dangerous concept here. The point is that focusing on the customer does not diminish the service to consumers in any way. Instead, it sets a frame and context for that service, turning it into a contribution to the customer’s needs. Often, the difference is subtle, but meaningful.
While a process engineer focused on consumers might design processes to avoid quality issues in from engineering or manufacturing teams, a process engineer focused on customers will seek to design processes to help his consumers deliver high-quality products to customers.
While an agile coach focused on the consumers might seek to implement Scrum (or whatever framework) with a team, an agile coach focused on customers will seek to enable the team to deliver to customers with improved service quality (might imply speed, volume, product quality, …) and reap business opportunities as they emerge.
While a QA responsible focused on the consumer might aim to avoid audit findings by rigorously checking all the formalities, a QA responsible focused on customers will seek to help teams bring products to customers quickly in a safe, reliable, and compliant way.
…
What sounds like a nuance can make a significant difference.
So, what is to be done? First and foremost, I think it is important to get clarity around who your customer vs consumer is, and maybe you have a bunch of other stakeholders that you want to differentiate clearly. Reflect on your current thinking and behavior: Who do you currently serve? Who do you have in mind when you define and deliver your services? This is especially important for internal services. Reflect: What would you do differently when you take the customer into the picture? How would that affect the consumers of your work? How would it affect your collaboration with them? And finally, whenever you hear someone talk about their ‘internal customer’: Flinch!
In a recent blog post, I explained how I ran monte carlo simulations on development projects in an attempt to underpin the ideal of “Improvement of Daily Work”. The simulations suggest that debt is the main factor killing all the projects that did not succeed. The mentioned post also brought up a lot of open questions, many of which concern the assumptions behind the simulation.
Hypothesis
There are different levels on which open questions remained: What are the parameters and functions that adequately reflect aspects like impact of debt on performance, interest rate of debt (how much more debt comes from existing debt?), how does investment in performance improvement really impact performance? Are there some universal parameters, even functions, after all? And is there a way to know what applies for a given endeavor, let alone in advance?
I do not have any objective information on either of these questions – and I doubt they even exist. So my hypothesis became that maybe, given the uncertainties around all these parameters, we need to find strategies that are less vulnerable to all those unknowns.
Changed Strategy and Parameters
So for the next set of simulations, I made one conceptual change: Instead of applying guard-rails for budgets, defining up-front how we distribute our capacity as a team to the three areas of (a) feature development, (b) debt reduction, and (c) performance improvement, this time we always fully pay down debt, then invest the remaining capacity along a defined ratio between (a) and (c). Note that “Improvement of Daily Work”, the Third Ideal as described by Gene Kim, basically consists of both (b) and (c).
Two subsequent tweaks have been made in addition:
Extended range of debt interest rates: While the previous simulation only covered debt interest rates of 0.1, 0.2 and 0.25 (see original post for more background), I added 0.5 for the fun of it this time.
Tuned down effectiveness of investing in performance: as compared to the last round of simulations, I reduced the effectiveness of investing in performance improvement by a factor of 0.75 (i.e. investment in performance improvement affects future performance 25% less than in the first simulation), after an initial run without such correction seemed to produce wildly unrealistic results.
In short, as you compare results with the previous simulations, keep in mind that this time we simulate higher debt interest rates AND lower impact from investing in performance.
Analysis
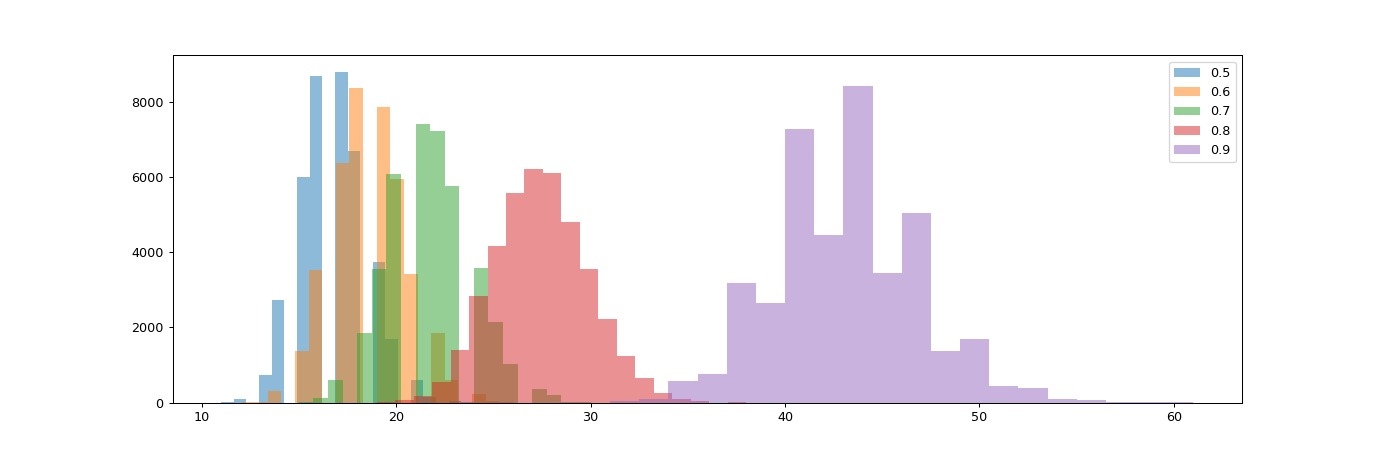
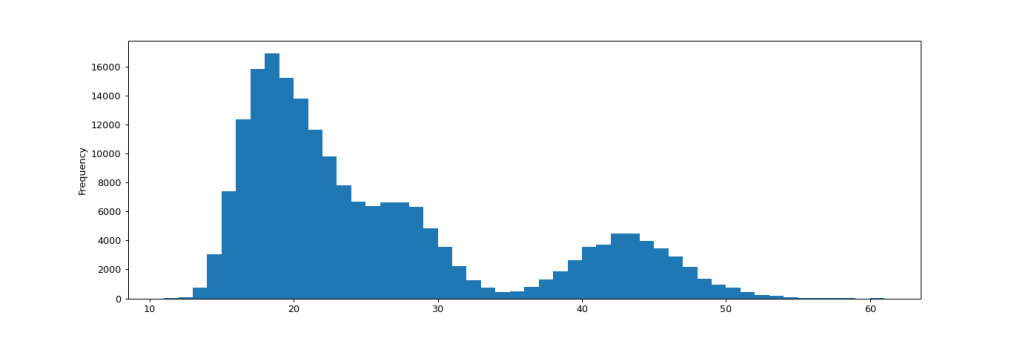
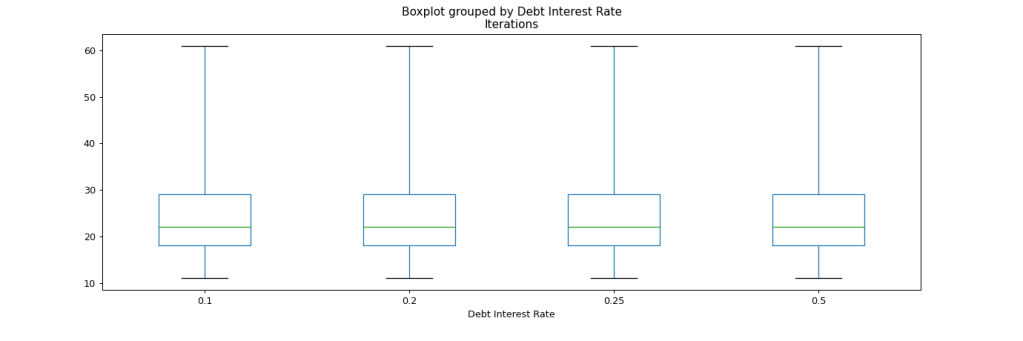
Even under these more difficult conditions, out of 200’000 simulated projects following the changed strategy, not a single one failed to deliver. The following histogram shows the frequency of each number of iterations used across all simulation runs. The slowest occurrence was completed after 61 iterations.
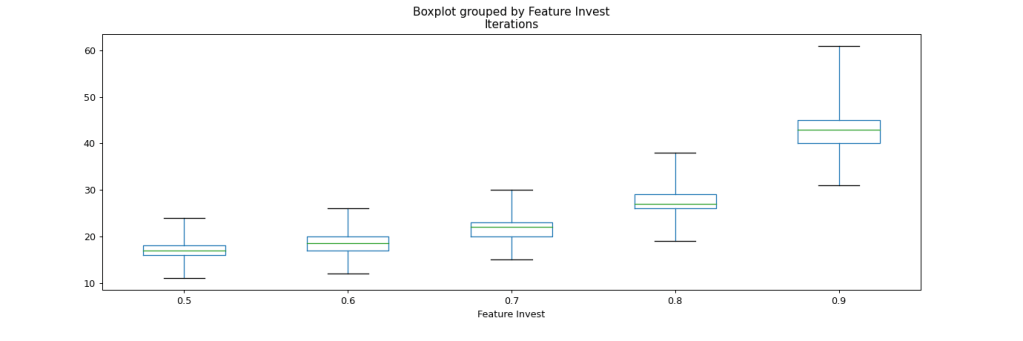
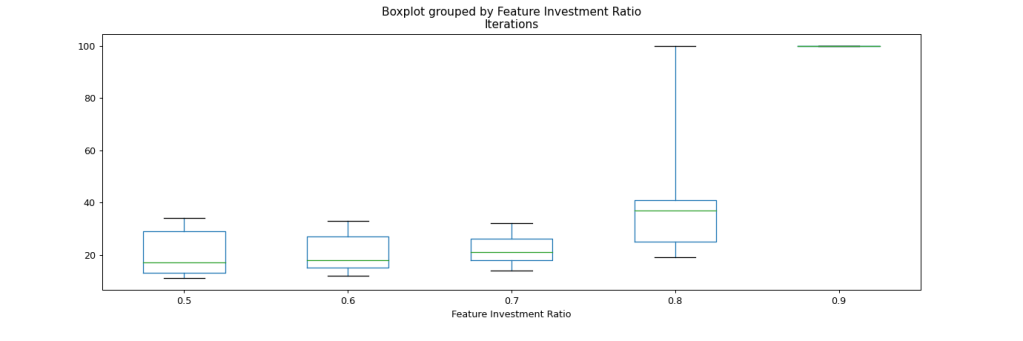
If we dig a bit deeper into how the number of required iterations is distributed, we find that we have a pretty consistent picture now. We still see the resemblance to a power-law distribution in the following box-plot chart, with higher shares of resources invested into feature development leading to longer development times. Note that in contrast to similar charts in the previous simulation, the max here is 61, not 100 iterations.
How many iterations are needed to complete the project scope, depending on how big a share of resources we invest in features over performance improvement? Green bars show the mean, blue box shows the 2nd and 3rd quartile, whereas the black whiskers show the min and max occurrences.
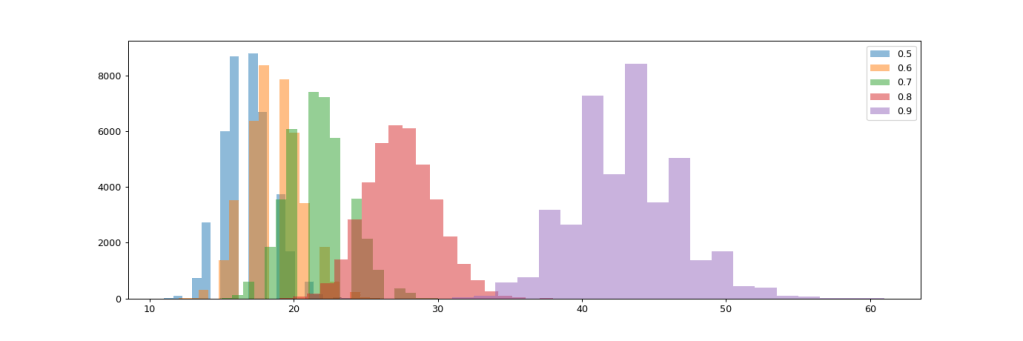
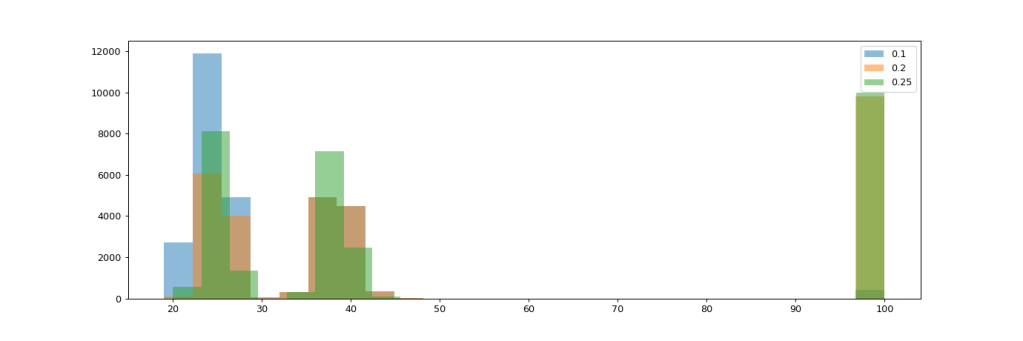
Splitting the histogram view per ratio invested into new features further visualizes the impact of this investment decisions. There are distinct distributions with a given mean per strategy.
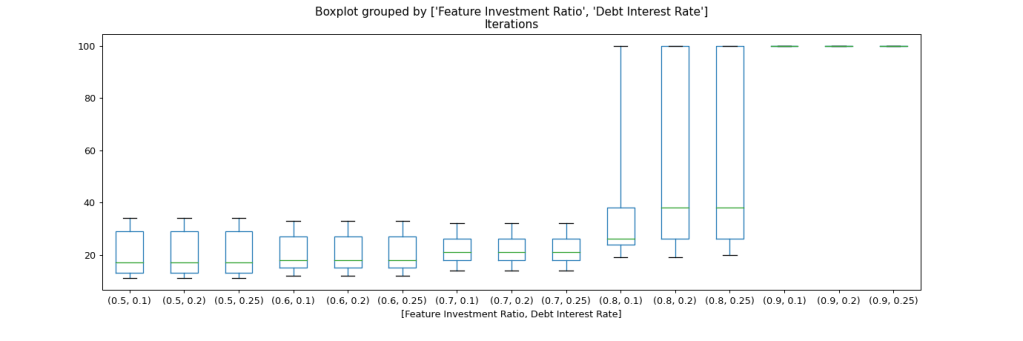
If we look at the distribution by debt interest level, we can see that with the new strategy of working down debt before any other investments, we completely rule out the impact of debt interest rates. There’s simply no difference in project trajectories whether the debt interest is 10% or 50%.
This comes as no surprise when we bring to mind that now we reduce debt to zero in every iteration, so debt interest never plays a significant role. Still this is a strategy I have rarely seen followed with great discipline in practice.
Conclusion
The “zero bug policy” that some organizations follow and many more discuss with great controversy is not so much an idealistic utopia as it is a mere life insurance.
And it’s not as much an idealistic utopia as it is a basic starting point, either. In order for it to really work well as a life insurance, we need to understand debt with a very broad definition, going way beyond “bugs”. Postponed refactorings are a form of debt as well as postponed documentation work, compliance aspects, you name it.
At least these newer simulations suggest that this will be the policy that greatly reduces your organization’s vulnerability around debt, particularly when those parameters are neither well known nor understood.
In a complex environment, the quest should not be to control the parameters, but to find strategies to deal with uncertainty.
Intending to underpin the relevance of “improvement of daily work”, I simulated a couple 100’000 years of development projects on my computer (487’462 years1, to be exact) in an attempt to combine ideas from two books: The Unicorn Project by Gene Kim et al, and Fooled by randomness by Nicholas Nassim Taleb. This led me on a trajectory that was not exactly what I anticipated. But let’s start from the beginning.
The Unicorn Project and DevOps’ five Ideals
In The Unicorn Project, the five ideals of DevOps are explained to us by a savvy bartender named Eric. Those five ideals are:
These ideals are powerful as they are easy for anyone to accept. Not much debate about whether simplicity, or focus, or improvement of daily work are a good thing. At the same time, they are also generic enough so that many people can relate their behavior to them. Many an executive agrees to the first ideal, then goes ahead and complects the organization with the next reorg in the belief to increase the organization’s ability to perform.
Improvement of Daily Work
As for the third ideal, improvement of daily work, I sense that pretty much everyone acknowledges the value of continuous improvement, yet under the pressure of target dates and the subsequent “tyranny of the urgent”, many don’t live up to it. “Yes, improving our daily work is important, but first, we need to just jot out those features for the next release. We will have time afterwards.”
I felt that he ideal of “improvement of daily work” lends itself nicely to simulations. Maybe through a load of simulated projects, we can generate insights that help take the right decisions?
The Relevance of Alternative Realities
In the attempt to get a point across, especially if counter-intuitive to the addressee, as in the example of “we should focus less on feature development and more on productivity in oder to get our features done sooner”, we usually refrain to some success stories and/or concepts explained in books. Such stories are often rejected with arguments like “that’s not us”, “that’s not going to work around here”, “we’re a different type of industry/product/company”, you name it. As annoying such reactions are, they are not necessarily wrong, because our approach is inherently prone to the survivorship bias. When we sell a success story, we look at one particular case (or a set of cases) where a behavior was correlated to a positive outcome. We ignore the cases where the same behavior was correlated to a negative outcome – mainly because of the lack of their visibility. We only see the “survivors” – so we only analyze the “survivors”, and we tend to infer wrong causalities. That said, a fair bit of skepticism is in order. For mentioned addressees, a fictional story does not help either.
In Fooled by Randomness, Taleb explains the significant impact that randomness has on our lives, and how we’re being fooled by it. When assessing our reality, we often look at a given situation as a result of past events that were bound to happen. We take what happened for the only thing that could have happened, ignoring randomness. This is misleading – because what happened is, after all, just one out of may sequences of events that could have unfolded.
The aim of a monte carlo simulations is to generate alternative realities, those that could have unfolded just as well, but did not happen to. Looking at a broad range of possible realities, we can then gain a better understanding about (a) which kind of result is more likely to unfold, and (b) which of our assumptions have the biggest impact on the results.
Insights
So I got hooked on the idea of creating a monte carlo simulator to simulate product development realities and hopefully show that investing in improvement of daily work pays dividends based on factors that are irrespective of your domain, business, product, or whatever. And maybe we could even find a sweet spot for resource allocation…
If you are interested in more details about the simulations, the assumptions made, and the thinking behind them, Appendix A outlines that in some detail. The Appendix might help better understand the insights presented in this section.
We want to see whether the simulations support the third ideal as stated above – “improvement of daily work”. I simulated different strategies of investing resources, allocating 50% to 90% of resources to feature development (in steps of 10%) and distributing the rest to performance improvement and debt reduction (see table in the appendix).
My first hypothesis was that we would see an optimum of resource allocation to features. Allocating too much would result in less optimization and hence slower completion. Allocating too little would also get us away from the sweet spot, as we would use too few resources to actually profit from all the improvements.
So let’s see how the number of required iterations is distributed across the simulations with similar allocation to feature development. These box-charts display the mean value (average amount of iterations) as a green line. The blue box depicts the quartiles above and below the average, and the black T-shaped whiskers reflect the max and min values.
On a first sight, our hypothesis is confirmed by the mean values increasing with each step in what resembles a power-law distribution. There are few interesting observations here:
In the simulated range, there seems to be no tipping point where the organization becomes slower due to a lack of focus on feature development. This, I find, is quite remarkable.
While the number of required iterations increases steadily with increasing focus on feature development, the variability is smallest at 70% resources allocated to features. (except for 90%, where all simulated projects fail).
We have failed projects only at 80% resources or above.
Next let’s see what the impact of the assumed interest rate on debt is. For this, we split up the graph further by interest rate and resource allocation to features.
We can see that the interest rate only impacts scenarios with 80% resource allocation on features. The mean jumps as well as the upper quartile as the interest rate moves from 10% to 20%, while further increase to 25% seems to have no significant effect.
Let’s have a closer look at the projects with 80% resource allocation to features next. The histogram shows the distribution of required iterations, split by debt interest rates (0.1, 0.2, 0.25)
While I was expecting to find a continuum of iterations needed, we find that there’s actually two distinct group of projects: They either complete their scope within about 45 iterations, or they don’t finish within 100 – which allows the interpretation that they likely would not ever finish, irrespective of how long we let the project continue. This pattern is surprisingly stable across all levels of interest on debt.
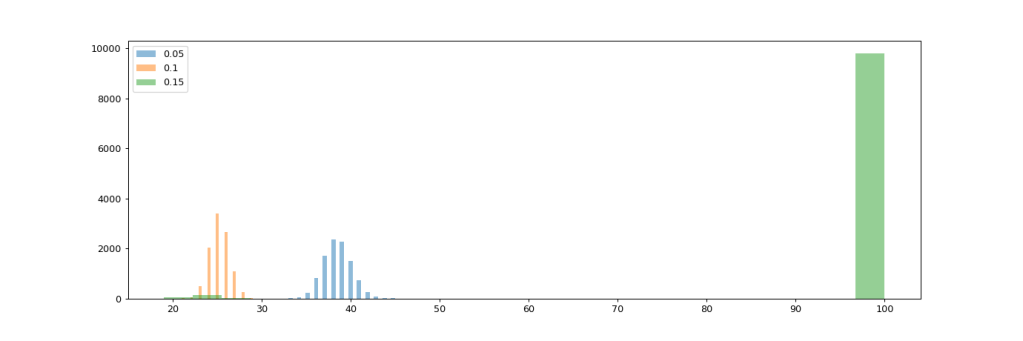
We’re still aggregating three different strategies to resource allocation here (refer to table above). I suspected that the two distinct bumps in the above histogram might be related to the different levels of investment in Performance improvement, so let’s drill down further in the scenario with 20% debt interest and analyze the impact of investing in performance improvement. My hypothesis will be that higher invest in performance improvement will lead to fewer required iterations.
Now this hypothesis is obviously not confirmed by our data. While investing 10% of resources in performance improvement seems to yield greater gains than investing only 5%, 15% performs worst of the three. In fact, all of the failed attempts come from the strategy with the highest invest in performance. So what’s going on there?
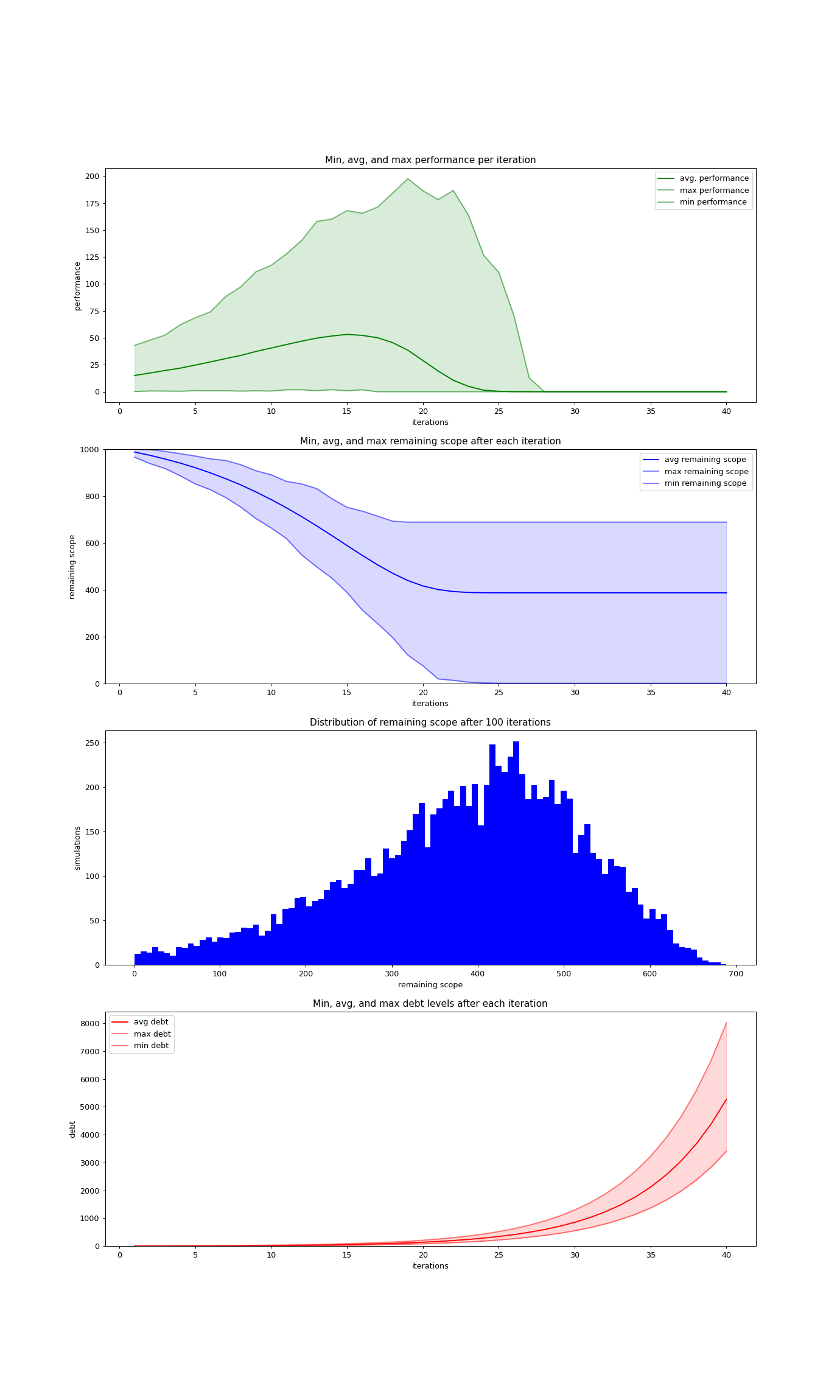
We need to look into the trajectories of those failed projects to understand the situation better. The following graphs display the average values of team performance, remaining scope, and debt for each iteration. The colored areas display the respective min and max values. In addition, the histogram gives an overview on the remaining scope after the 100th iteration.
These graphs do tell an interesting story. It seems that for all the failed projects, the build-up of debt eventually impedes the team performance to the point where no progress on features is possible anymore, and debt continues to accumulate.
Conclusion
From the simulations and analysis done so far, I draw two conclusions:
The data seems to suggest that Improvement of Daily Work is certainly worth pursuing, and – counter to my expectations – I haven’t seen a “tipping point” where too much invest into improvement of daily work becomes counter-productive. All this, however, holds true only as long as you have your debt under control. Keeping quality in check (any aspect of it) is a precondition for the third ideal to play out.
There are more open than answered questions on this.
Open Questions
How does the assumed impact that debt has on performance affect the results? And what would be a fair assumption to make about that impact? It could potentially change the trajectories significantly.
How does the invest in productivity actually pay back in terms of improved capacity? The assumption taken for the simulation is pure gut-feeling and might impact the results if changed.
Also, what would actually be a fair value to assume for the interest rate of debt?
For any of those assumptions, do universal values exist at all? Is there a way to know up-front, so that we can optimize our investment strategies to such values? Or will we rather need entirely different strategies to allow dealing with the unknown and unknowable?
The simulation uses mostly linear models – how accurate are they, and how does this (lack of) accuracy impact the results? E.g., can we assume that investing twice as much in performance improvement yields twice the return in terms of improvements? Isn’t the potential for improvement exhausted at some point, both when increasing the invest as well as over time? On the other hand, couldn’t investing more also unleash exponential improvements that were otherwise never possible?
The list goes on and on, and I sincerely hope to be able to run more simulations and come up with more insights over time.
As for now, the take-hope message is limited to this:
Keep your debt in check
Pursue improvement of daily work
You likely overestimate the impact of investing into features for your overall progress.
Appendix A – Simulating Product Development
First of all, I decided I would simulate endeavors with a set of starting conditions:
In every endeavor, a product backlog of 1’000 story points needs to be “worked down”. Since we don’t assign any actual scope to the number, for the sake of the simulation it is irrelevant how stable that backlog is content-wise. Also it would not impact the simulation if the backlog would be built up continuously over time, assuming that the team does not run out of work throughout the simulation.
In every endeavor, the Team starts with an initial capacity of 20 story points per iteration.
We will simulate a max of 100 iterations for each endeavor. If the product backlog is not fully “worked down” by then, the project’s considered failed and the simulation is stopped. With a backlog of 1’000 story points and a capacity of 20 story points per iteration, the backlog would be expected to be done after 50 iterations.
Note that the actual scale of the simulation is irrelevant – whether it’s a single team with a product (fairly small story points), or a large, multi-team organization building a huge product (fairly large story points) makes no difference.
Further note that the iteration can account for a large variety of setups. For an organization using Scrum, tit might be a sprint of whatever length. However, it might just as well reflect product increments in a SAFe environment, or a regular cadence in which we observe and measure a system based on continuous flow (Kanban).
Capacity, Productivity, Debt, and Features
Capacity vs. Productivity
Capacity in our simulation means the amount of story points that a team would be expected to work down during an iteration under expected circumstances. Most scrum teams, for example, assess their team’s capacity for a sprint based on recent performance, absences, etc.
Reality rarely follows the plan. Unplanned absences but also under- or over-estimated work items impact the teams ability to deliver. In the simulation, we refer to the amount of story points that a team is actually able to deliver as its productivity.
This is where Monte Carlo enters the picture: By subjecting the theoretical capacity to a degree of randomness (called “success factor”) in each iteration, we get the simulated productivity.
As the legend goes, a team that does not invest in its productivity will eventually, by laws of thermodynamics and due to entropy, reduce it’s capacity to deliver. I don’t know of any research about this (if you do, please leave a link in the comments!), but the legend is so popular that the simulation accounts for this, too.
Dealing with Debt
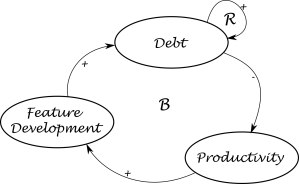
From a qualitative perspective, we can say that:
When we build features, inevitably, we will build up some debt. Technical debt, but also quality debt. In our simulation, all debt is combined in a single value, and we track it in the currency of story points for reasons of simplicity.
Debt leads to more debt – an issue that easy to fix right away will be much more difficult to resolve a few months down the line. Also, technical debt that we decide to work around instead of fixing will be more severe afterwards, because to fix it, we will also need to fix the workaround eventually.
Debt reduces productivity – the more debt that’s in the system and that needs to be (a) managed and (b) worked around, the more difficult it is for the team to get stuff done. The simulation accounts for this by having debt impact the capacity for every iteration.
Causal Loop Diagram. Feature development leads to the build-up of debt, which in turn adversely impacts performance, which drives features development. Debt, with age, increases, so debt creates more debt.
Simulating different Strategies
The simulation allows to define how the productivity of a team is invested in three different areas:
Feature Development: The share of the team’s productivity that goes into reducing the feature backlog.
Debt Reduction: The share of the team’s productivity that goes into reducing already built-up debt. This represents reducing technical debt, documentation debt, but also quality debt like fixing bugs.
Performance Improvement: The share of the team’s productivity that is invested in measures to drive up the team’s capacity in the future. This reflects work like automating repetitive tasks, creating or shortening feedback loops, investing in continuous delivery capabilities, measures to improve collaboration, etc.
Note some limitations in the simulation:
How the productivity of a team is invested across these three categories remains constant throughout the simulation. For the sake of simplicity, we derive the productivity from the capacity as described above, then split the productivity according to the defined strategy and apply it to calculate the iteration’s outcomes.
As a consequence of (1), the variability is limited to the “success” of the sprint. Some sprints might deliver 0 results, other might result in a firework of stuff done.
Also as a consequence of (1), when the capacity assigned to debt reduction exceeds the actual debt, the excess capacity is lost for the iteration. This fact penalizes high invest in debt reduction.
Investment in performance improvements affects the capacity of the team for upcoming iterations.
To avoid dealing with decimal places in remaining scope values, the simulation always rounds capacity to a natural number. The simulation, on the other hand, does not account for the usual Fibonacci-like series applied with story points.
So far, the simulation covers 13 different strategies, a combination of 50% to 90% of capacity invested in feature development, and the rest either in favor of debt reduction or performance improvement, or balanced between the two. For each investment strategy, the simulation runs 10’000 projects. The simulation stops when the backlog becomes empty (i.e., 0 story points), or after 100 iterations.
Feature Development
Debt Reduction
Performance Improvement
50%
40%
10%
50%
25%
25%
50%
10%
40%
60%
30%
10%
60%
20%
20%
60%
10%
30%
70%
20%
10%
70%
15%
15%
70%
10%
20%
80%
5%
15%
80%
10%
10%
80%
15%
5%
90%
5%
5%
13 simulated strategies for investing in the three areas
A word on the randomness
In order to make the different strategies more comparable, I seed the random generator identically for each strategy, so that each simulated set of projects is subjected to the same set of “realities”.
Assumptions
The simulation necessarily builds on a set of assumptions that might significantly impact the results. Among them:
Debt Interest Rate: How much does the load of existing debt grow if it is not tackled? I ran simulations with three different rates:
10% – while 10% seems a lot, it effectively means a duplication after ~7 iterations. That would mean a bug that an be fixed in half a day if we just tackle it right away, will need require a day of work 7 iterations later. Without further data at hand, my gut-feeling is that this is a rather optimistic assumption.
20% – means a duplication every 4 iterations, so in this case, some clean-up or bug-fix that we postpone might be twice as much work to get rid of after 4 iterations.
25% – means a duplication every 3 iterations, which feels rather pessimistic to me.
Debt from new features : How much is the ratio of debt created from new features? For now, I worked with the assumption of 10%.
Debt impact on productivity: How does debt affect the teams capacity/productivity? Lacking real-life information, the simulation uses a shortcut here: The ratio of invest impacts the performance directly. If you invest 100% in performance improvement, then the performance doubles every iteration (well, almost, because of the drain). This is clearly a very simplistic way of modeling this.
Performance drain: How much does the performance drain if the team does not pay attention to it? I simulated all runs with a drain of 1% per iteration, which effectively means the performance would be reduced to half its value after 69 iterations.
1 12’708’831 simulated iterations, assuming 2 weeks per iteration results in 25’417’662 weeks or 487’462 years.
The discussions around tracking effort for work items of any kind in (new) product development seems to never cease. In this article, I try to lay out why tracking effort is likely a waste of time that does not help your product in any way.
Why do we track effort spent per work item anyway? There are two answers I hear regularly to this question:
in order to learn and optimize our output
in order to increase predictability
The following two sections will dig in each of these perspectives.
The Optimization Perspective
A common rationale for time tracking is the wish to get information in order to optimize the output. Let me give a bit of context to explain why effort tracking will not help for that.
A nice way of analyzing the efficiency of processes is Value Stream Mapping. A bit simplified, it maps the various steps a work item goes through and reflects average touch-time and wait-times. For example: After some refinement activities (one half-hour actual discussion during a two-hour meeting) and waiting for another two weeks in the Backlog, a work item might be loaded into a two-weeks sprint during planning. It might require a day to implement and another day for testing and documentation. After the Sprint, it will wait an average of 10 days until it gets deployed in the monthly deployment cycle.
An exemplary, simple value stream map.
In this exemplary excerpt of a value stream, we can identify that the item resides 31.25 working days in the process while being worked on for 2.2 days. This information allows us to calculate a metric called flow efficiency, which is the percentage of time an item is actively worked on (touch-time) as compared to the time that item resides in the process (lead-time). In our example that would be approximately 7%. This is a pretty representative number. In fact, we rarely see flow efficiency exceed 15% where it is not very consciously managed.
Additionally, let’s be aware that the meaningful figure for customers (those who pay our wages eventually) is actually the lead-time. Once decided that something is going to be done, the question “When will it be available?” is much more relevant than “How much effort is it?”.
All this implies that if we focus on optimizing the touch time, in our example we optimize about 12% of the lead time that is relevant to customers. The bad news here: it’s the 7% that are hardest to optimize. What we should do instead is to optimize our system to get rid of a big share of the 93% wait-time. To spend less time doing nothing with a work-item is typically much easier than doing what needs to be done faster.
To make things worse, tracking effort does not even give us any clue with regards to how to do things better. All it can show is that an item took more effort than expected. But frankly, engineers do know this anyway. Unless we operate in a system built around mistrust, why would we need to track numbers to prove to engineers that a task took longer than they expected it to take? I can’t think of an answer to this question.
Put short, from a perspective of optimization, tracking effort puts our focus on the wrong spot plus gives us no valuable information what to actually do differently. Instead it reinforces a culture of blaming much more than one of actual learning and continuous improvement.
The Predictability Perspective
The other argument I often hear is that we want to use the data to compare it with estimations in order to learn and improve predictability. While improving predictability is a worthy goal, tracking effort will not get you significantly ahead.
Drawing on the value stream mapping example from above, it becomes obvious that even if we rigorously apply analysis to estimated vs effective efforts, we only get information about 7% of what makes our lead-time – the one that we actually need to do predictions on. So even if I reduce error margins for this part, how much more predictable will I be over all?
Again, the better approach here is typically to reduce wait-times. Reducing wait-time also increases the predictability, but without trying to overcome the actual nature of innovative product development, which inherently volatile with regards to efforts. Another approach to reducing uncertainty with regards to the lead-time is typically to reduce batch-size. Split one task into multiple smaller ones that will show less variability.
What makes predicting effort difficult is the very nature of product development. We aim at building something new, something that hasn’t been there before. That makes it fundamentally different from other types of work like manufacturing, where we see much more repetitive tasks. As Don Reinertsen explains in “The Principles of Product Development Flow”: In product development, there is no added value without variance.
So, let’s face the fact: Taking pride in innovation power and at the same time asking for high predictability is kind of schizophrenic. And our the level of schizophrenia admittedly depends on the individual context, let’s acknowledge that basically we can have one or the other, but not both. And in the context of (new) product development, innovation needs to get priority.
Conclusion
What good is it to invest precious time in administrating effort spent on tasks, when all we can gain is a mere few percentage points improvement in predictability? Once more, Frederick W. Taylor’s ideas of scientific management prove outdated for today’s environment and the nature of knowledge work. Taking a more systemic perspective, we find that tracking effort actually tends to misguide our focus to the wrong aspects while even negatively impacting a collaborative learning culture.
So, what to do instead? Here’s a few proposals that certainly don’t make up a comprehensive list:
Shape a culture of mutual trust that allows for real learning and continuous improvement
Focus on lead times rather than effort. Focus on velocity (i.e. how much of our estimatied volume are we able to deliver in a defined amount of time) rather than effort, as velocity inherently puts lead-time in the focus.
Optimize lead-times where it actually counts: Figure the granularity that reflects actual added value delivered to your customers. This is typically rather coarse grained than fine grained.
Gain predictability and improved output through rigorously reducing waiting time.
But most certainly: Stop (or don’t start) doing what is not helpful.
I talk to plenty of people struggling with the
idea of planning in an agile environment. It seems hard to get the balance
between not planning at all and planning on a level of detail that requires to
take all sorts of assumptions concerning a relatively unknown future. A while
ago, I did plan for a sailing trip, and it dawned on me that all too often, project
plans are carved out as if we could predict the weather on a specific day years
in advance.
We started planning for a 2-weeks sailing trip long before the actual cruise (aka project execution) – about a year in advance. We knew we’d take the boat on a certain date from Tromsø and would have to pass it on to the next crew two weeks later in Bodø, preferably in a good shape. These hand-over dates and places where actually not under our control. We knew we wanted to experience the midnight sun – that was part of our “vision” for the cruise.
Also, we had only limited control over the crew (aka. Team) – something experienced by many projects, too. A part of the crew had been sailing together before. But then there were more people signing up that we hadn’t even met before, because the boat bears space for more than our known crew. (Think self-assignment for the team.)
This reflected the first, high-level plan for our
trip:
Take on the boat in Tromsø on 11th July
with a crew of seven people, two of them practically unknown to us. New hires, so to say.
Hand-over the boat in Bodø on 25th July.
Travels to and from the Boat organized individually; we would meet at the boat at the given time.
Being responsible for the navigation during the trip, the next couple of months it was my job to take the planning to a next level. I needed to get an understanding of the situation in the area. I collected information from all possible sources, very similar to a PO trying to understand the market for his product.
I cared about stuff like:
A PO would care about stuff like:
What documentation (sea charts, cruse guides, web sites, …) existed and seemed useful?
What Routes exist to get from Tromsø to Bodø? Which of those would fit the boat we had? This is a good time to avoid finding yourself in front of a 15m bridge when you already know you’ll have 20m mast-top height, for example.
What are the general currents and tides in the area?
Which harbors, bays, etc. are on the way? How exposed are they to different weather situations? What infrastructure is available where? Where can you restock on food, water, and diesel, …? Where can you recharge batteries?
What sources exist to learn more about the demand of my potential customers?
What products already exist in my field? What do users like/dislike about them?
Is there a market for my envisioned Product at all?
What is my value proposal? What are my differentiating factors?
What are people ready to pay for comparable products?
What are the trends in the market I plan on tackling?
Who might be ready to invest in my endeavor?
Where and how to get the required resources?
Once Options got clearer, I needed to decide for
a preferred route, including a rough sketch of the daily legs. It was a given
we had to go south, not much options there. No matter if the weather was ideal
for this direction. Important aspects for the selection where, amongst
others:
Which places did we really want to visit? E.g., we wanted to see the Trollfjord, we wanted to do Whale-Watching in Andenes, and some others.
Which route fits the capabilities of the crew (team) and the boat (infrastructure)?
Which route offers plenty of options on the way in case something unexpected happens?
How frequently can we re-fill our tanks and stock-up on food?
How can we split the whole trip into sensible legs for each day, allowing for some days on shore? (Shore-days are good for some sight-seeing while at the same time they add contingency to the plan).
I decided to opt for the route going down the
inside of Vesterålen and Lofoten islands for reason of better shelter and less
exposure to the open arctic sea, plus more options for infrastructure and
alternative harbors and bays, based on the actual weather. On the downside,
this meant a slight detour to get the Whale-watching dream to become reality,
but we gladly traded this in for safety and comfort of both crew and boat.
This first plan is a bit like an initial Backlog.
It leaves plenty of room to adapt on any situation once you know more about the
actual reality you find yourself in.
In the days before getting on the boat, we started
consulting the weather forecasts on a regular basis to figure how the weather
would affect our route. Would it allow to follow our plan or force us to adapt?
Now would have been the time to adapt and chose an alternative basic route in
case needed, building on the knowledge acquired through the previous planning
activities.
Once on the boat, it is good practice to prepare a “passage plan” for each leg, day by day. Taking into account the latest weather data, the crew’s and the boat’s current condition, currents, tides, and the overall plan and framing conditions (like: the boat needs to be in Bodø by 25th July), one plans the target position for this next leg, the supposed route to get there, and any alternatives available in case something unexpected happens. We can compare this to a Sprint-Planning, and indeed if we use the whole cruise as an analogy for a project, then the leg must represent the iteration.[1]
Out on the water, the cruise is like a series of
standups all the way. Constantly you’re checking what course you can actually
sail, what drift you really have, what true course this represents (which might
be nowhere near your passage plan). You will watch the weather, wind, and sea
state as it evolves, and continuously reassess whether you need to adapt your
plan. You might hit an unexpected rock, something on the boat breaks, or an
unexpected storm comes up, and the situation forces you to react. Out on the
ocean, it seems much more natural that the number of things that can happen to
you are beyond imagination, and you will need to be prepared at any moment to
abandon your plan, because it obviously isn’t in line with reality anymore. For
some reason, it seems to be much harder to acknowledge a similar situation in
business endeavors. However, plenty of stuff can happen that impacts your
market to the extent that your plan simply renders useless. It might be as
simple as a competitor launching a new product to as fundamental as an economic
bubble bursting.
In today’s world, your market, including your user’s requirements, might be similarly volatile than the weather on the ocean, and can turn just as quickly. Your market analysis will be by far less accurate than any sea chart published – and yet many expect we can plan for projects and define product requirements well ahead, while a sailboat touching ground from time to time comes as no big surprise.
The bottom line here is that when it comes to planning, we should be very mindful about our assumptions. There’s nothing wrong with a bit of up-front planning – quite in contrary. If you plan based on the stable or slowly-changing dimensions in your environment and leave enough room to navigate according to the more volatile aspects once you’re on the spot. This might feel like losing control, where in fact it’s only losing imaginary control. Let’s confront the brutal fact: none of us will control the weather – or a market, for that matter – anytime soon. Let’s rather set ourselves up so that we can deal with whatever reality has on stock for us.
My lesson from Sailing is this: Think of
long-term plans as a tool that enables tactical short-term planning leading to
an envisioned end. There’s no way we could have delivered our boat in-time to
Bodø without much of the early planning efforts. And the reliability of any more detailed early plans would
have been questionable at best.